Si te has metido alguna vez en el mundillo de la IA local, seguro que te has hecho esta pregunta: vale, pero ¿qué modelos puedo mover yo con mi ordenador?
Ahí es donde entra CanIRun.ai, una web creada por midudev que intenta responder justo eso. Entras, detecta tu hardware desde el navegador y te muestra una estimación de qué modelos de inteligencia artificial podrías ejecutar en local, cuáles irían cómodos y cuáles directamente se te quedarían grandes.
Qué hace exactamente
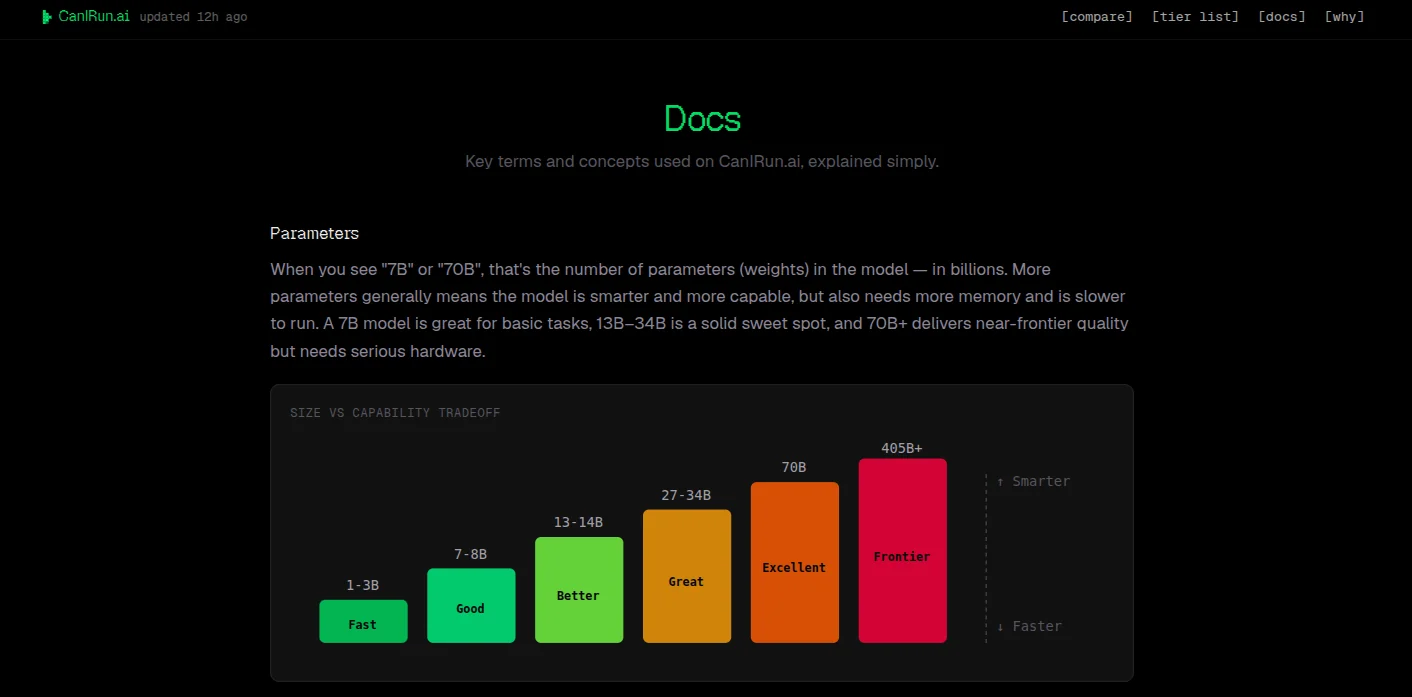
La idea me parece muy buena porque ataca un problema real: mucha gente oye hablar de modelos de 7B, 14B, 32B o 70B, pero no tiene claro cómo traducir eso a su máquina.
CanIRun.ai intenta simplificarlo:
- Detecta tu GPU, CPU y memoria desde el navegador
- Calcula cuánta memoria necesitaría cada modelo según su cuantización
- Estima si ese modelo entra bien, entra justo o no entra
- Te enseña una calificación por letras para orientarte mejor
Todo con una interfaz muy directa y sin obligarte a instalar nada.
Lo interesante de la propuesta
Lo mejor de esta web es que no se queda en el típico "tu gráfica tiene X GB". También intenta aterrizar conceptos que para mucha gente siguen siendo algo confusos:
- La diferencia entre tamaño del modelo y rendimiento real
- El impacto de la cuantización (
Q4_K_M,Q6_K,Q8_0, etc.) - La importancia de la VRAM o de la memoria unificada en Apple Silicon
- La velocidad estimada en tokens por segundo
Además incluye una sección de documentación bastante útil para entender términos como MoE, contexto, ancho de banda de memoria o formato GGUF.
Por qué puede venirte bien
Si estás pensando en usar herramientas como Ollama, LM Studio, llama.cpp o similares, esta clase de web te ahorra bastante prueba y error.
Porque una cosa es que un modelo "arranque" y otra muy distinta que sea usable en el día a día. A veces un modelo cabe por los pelos, pero va tan justo de memoria o tan lento que la experiencia es mala. Y eso CanIRun.ai intenta reflejarlo con su sistema de puntuación.
Me parece especialmente útil para:
- Gente que quiere empezar con IA local y no sabe por dónde tirar
- Usuarios de portátiles con GPU modesta
- Equipos con Apple Silicon, donde la memoria unificada cambia bastante el escenario
- Curiosos que quieren comparar si les compensa probar un
8B, un14Bo dar el salto a algo más grande
Ojo: son estimaciones, no magia
Aquí también conviene poner el matiz importante. La propia web deja claro que sus resultados son estimaciones basadas en APIs del navegador y que el rendimiento real puede variar.
Tiene sentido: no es lo mismo usar un modelo con más contexto, otra cuantización, una configuración distinta o una herramienta diferente. Tampoco rinde igual en todos los sistemas ni con todos los drivers.
O sea, no lo tomaría como una verdad absoluta, pero sí como una referencia rápida bastante útil para no ir totalmente a ciegas.
Un detalle que me gusta
También me parece interesante que el proyecto explique cómo hace sus cálculos. En la sección Why detallan qué datos detectan, cómo estiman el consumo de memoria y cómo construyen la puntuación final.
Ese punto de transparencia suma bastante, porque no es solo una lista bonita de modelos: te deja entender el criterio que hay detrás.
Mi impresión
CanIRun.ai me parece una herramienta muy práctica para cualquiera que tenga curiosidad por la IA en local. No sustituye las pruebas reales, pero sí te da una primera orientación muy útil en pocos segundos.
Y en un tema donde es fácil perderse entre tamaños, cuantizaciones, VRAM y nombres de modelos, una web así tiene bastante sentido.
Y además tiene ese punto extra de venir de alguien como midudev, que suele publicar herramientas y recursos bastante chulos para desarrolladores.
Si te interesa este tema, échale un ojo: canirun.ai.